Gray's "Elegy" in translation: a multilingual digital humanities project

Thomas Gray's "Elegy Written in a Country-Churchyard" (1751) is, according to the Digital Miscellanies Index, the most anthologized poem of the eighteenth century and one of the most widely and frequently translated, paraphrased, and imitated poems in the English language. With to date at least 266 translations into at least 40 languages, the "Elegy" has inspired translators ever since the earliest translations into Latin appeared in the early 1760s.
The aim of the "Gray's 'Elegy' in translation" project is to make it possible to trace and document the reception and impact of Gray's most famous poem in a number of languages and national literatures. Drawing on the extensive collection of "Elegy" translations compiled by Tom Turk, the purpose of this work is firstly to enable the study of the evolution of translations of the poem in a single language and culture, and secondly to allow for a comparative study of the translations across languages and literatures, initially within, but ultimately beyond European boundaries.
In the first phase of the project I have covered the period up to 1805 (apart from a number of lacunae), comprising 57 verse and prose translations of the "Elegy" in eleven languages (Danish, French, German, Italian, Latin, Polish, Portuguese, Russian, Spanish, Swedish, and Welsh). I plan to extend this range to the 1830s and beyond (adding many more translations and languages) in future phases of the project.
The full-text of each translation is accompanied by a short note on prose or verse form as well as bibliographic information about the source edition, which can also be consulted in the bibliography. All texts have been marked up in TEI/XML for long-term access, re-use, and preservation purposes.

Apart from transcription, proofing, and markup, the single most labour-intensive part of the project was aligning equivalent passages of the original text with the 57 translations, stanza by stanza, or paragraph by paragraph in the case of prose translations. Over the course of the project, a number of strategies were tested and applied depending on both form and content of the translation. I was surprised by the sheer expressiveness and variety of the translations, from the literal and faithful (sometimes even mimetic of both form and content) to the summative, recreative, and wholly adaptational.
I quickly had to revise my original (untested) hypothesis that by identifying a few memorable content words and phrases in each of the stanzas/paragraphs, I would be able to align stanzas even in languages unfamiliar to me. Instead, I found formal characteristics to be far more reliable and actionable properties. The length of the translation, the choice of stanzaic form, the type of metre and rhyme pattern all provide invaluable orientation. Translators may have opted to mimic, recreate, or completely abandon metrical and rhyme properties for a number of receptor-language-specific reasons, and only a detailed study of the individual case will allow for more substantive comments. Surprisingly (at least for me), however, it was the freer prose translations that in the end proved to be the most difficult to get to grips with and which often required the help of automated translation.
Thankfully, due to continual advances in machine learning (ML) and the ready availability of APIs and command-line tools, automated translation isn't quite as cumbersome and frustrating an experience as it was only a few years ago. Google's cloud-hosted Datalab service, for example, offers a wide range of ML applications, particularly for data science, among them a pre-trained translation engine for more than 100 languages. With a bit of command-line magic we can firstly extract, and subsequently submit and retrieve translations (here an example in programming language Python to retrieve a German translation of the first stanza):
from google.cloud import translate
translate_client = translate.Client()
result = translate_client.translate (
"The curfew tolls the knell of parting day,"+
"The lowing herd wind slowly o'er the lea,"+
"The ploughman homeward plods his weary way,"+
"And leaves the world to darkness and to me.", "de" )
print ( u'Translation: \t{}.format (
result[ 'translatedText' ]))
By supplying different parameters, it is easy to imagine further automation of this task, something I am keen to investigate for subsequent phases of this project. The results have been found perfectly adequate for the task of equivalence alignment at hand.
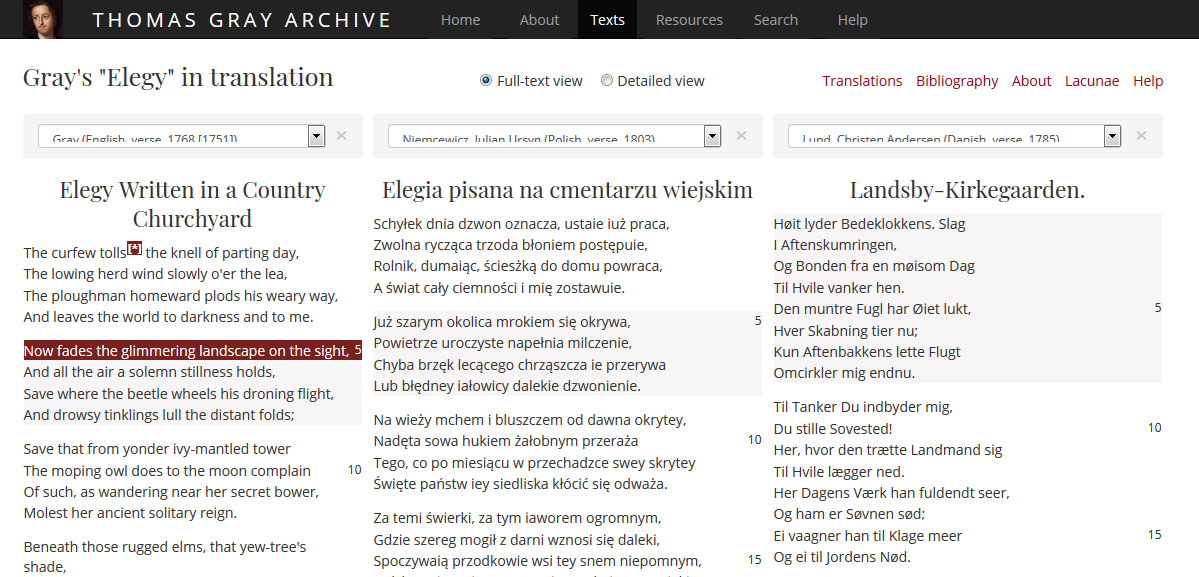
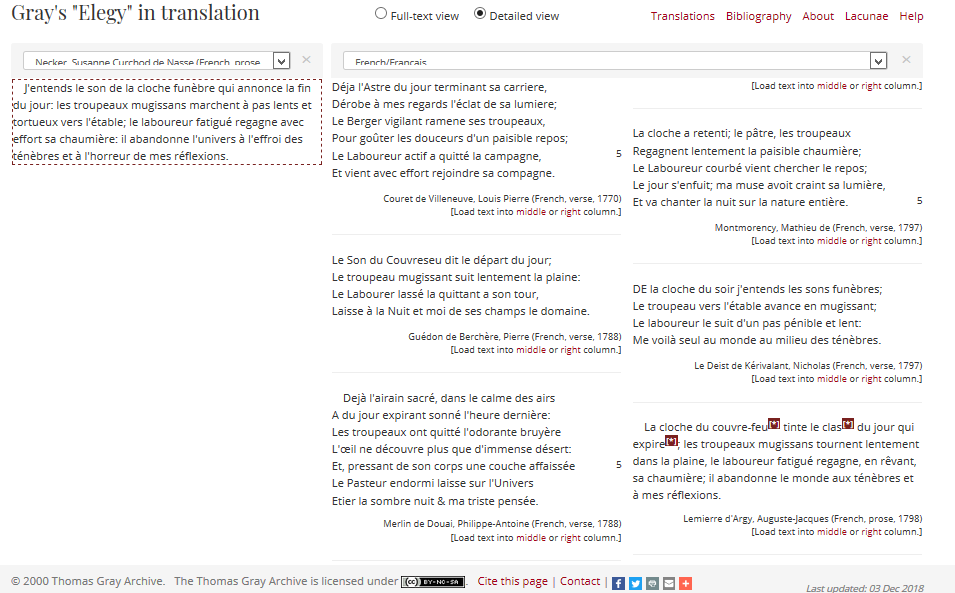
The two main objectives for the project website were to provide an intuitive interface to the translations that allows for easy comparison of equivalent passages and to allow users to comment on any part of the original or any of the translations. To this end I have implemented two related interfaces, a full-text and a detailed view, which can be selected from the top of the translations comparison page.
In the full-text view up to three texts (in any combination of languages) can be explored side-by-side in their entirety, "equivalent" passages are highlighted when hovering over any stanza or paragraph. In the detailed view any one stanza from any text can be compared with its "equivalents" (if available) in either all of the translations or the translations in a particular language. Users can also add a translation or comment on a translation of any section of any of the texts using a simple click and drag action to mark the section to be annotated.
57 translations down, only 200 or so more to go... I would love to gain a better understanding from practitioners on which avenues to pursue (linguistic, stylistic, semantic etc.) for both the enhanced markup of the translations and the development of tools (and/or integration of external services, such as dictionaries/thesauri) to provide via the interface.
Having caught the multilingual bug, I am also very keen to expand another resource of which I am editor, the award-winning Eighteenth Century Poetry Archive, to include poems in other languages, along with tools for their analysis. Anyone reading this who might be interested in contributing to this endeavour, please get in touch! I hope you will have a chance to explore the translations, and would love to hear about any changes, improvements, or additions you would like to see in the future. Please do not hesitate to contact me with your feedback.
Alexander Huber is a digital librarian and eighteenth-centurist working in the digital library programme of the Bodleian Libraries at the University of Oxford (BDLSS). He is also the editor of the Thomas Gray Archive, a long-term research project devoted to the mid-eighteenth-century poet, letter writer and scholar, Thomas Gray.
Main image source: The British Library [No restrictions], via Wikimedia Commons
Where next?
Finding poetry in a new language